Consulting - Quality
Difference makes the DIFFERENCE
Introduction
The pre-cursor to Machine Learning is Expert Systems which has inherent limitations. Owing to these limitations, We Humans, have come up with the idea, of providing data to the computer, and computer decides, which algorithm to apply, and, which functions to work upon. This has greatly reduced our work, by limiting us, just to provide proper data to the computer.
Now, Machine learning, has become a buzz word in the market, and is filled with variety of Jargon.
Here are a couple of definitions for Jargon. https://youtu.be/_eXH3FNeOs0
0. JARGON JAR
A Jargon is: a set of special words, or expressions, used by a particular group, that are difficult for others to understand.
another definition is: a type of language that is used, in a particular context, out of which, makes no sense.
For a detailed understanding on ML jargon, I suggest to search on YouTube for the key word, “Jargon Busting”, from One Fourth Labs
The Mentors has diffused this confusion into 6 Jars, they are: Data Jar, Task Jar, Model Jar, Loss Jar, Learning Jar and Evaluation Jar. The entire subject of Machine Learning can be etched into these six jars
Now, for a primary understanding, let us study each one of them. In previous days, we had to pay for test data, but now, we have abundant data readily available. It depends on our skill, as to how we see this data and analyse it.
1. DATA JAR
at Stage 1, or at Data Jar stage, we need to confirm to certain questions before we proceed on…
- What data do we have at hand?,
- What is the task that should be done with this data?
- Does the data satisfy the requirement conditions?
- If the available data is insufficient, how do we make it sufficient?
are some of the primary questions that needs to be addressed.
Hence, in this role, our prime role is to get the exact data to suit the given requirement.
2. TASK JAR
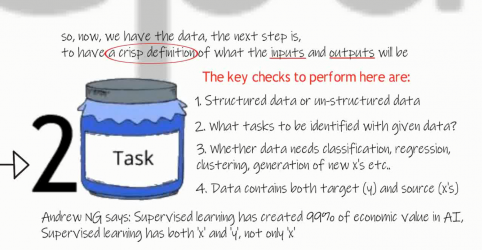
Now, we have data collected and cured, to the required extent. Next comes, stage 2, or, Task Jar stage, where, we need to have a crisp definition, of all the inputs and given outputs. We also need to identify, the number of tasks, that can be derived, out of the given data.
Some of the key checks to consider, before working with the data, are,
- to know if the data is structured or unstructured,
- which of the identified tasks to be classified,
- which are to be clustered,
- which are to generate new x’s, which needs predictions, and so on…
Remember that, Machine learning, is highly successful with supervised learning. Meaning, we should have both the X’s and Y’s.
3. MODEL JAR
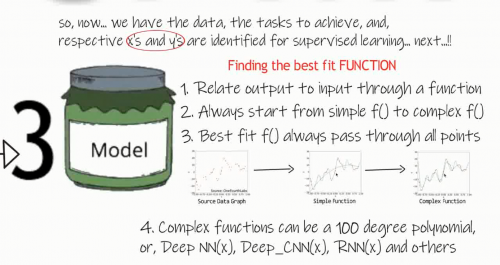
Now we have the data and tasks identified. Next comes, State 3, or, Model Jar. Here we try to find the best fit function, which can pass through all points in the data graph. Not each point of course…
a few cautions to remember:
- always relate input output and input through a function
- always start from simple function and move on to complex function
- Best fit always passes through most of the points
Complex functions may include Deep Neural Networks, Deep Convolutional neural network, Recurrent neural network and so on.
Machine Learning
6 Jars to Diffuse Confusion
4. LOSS JAR
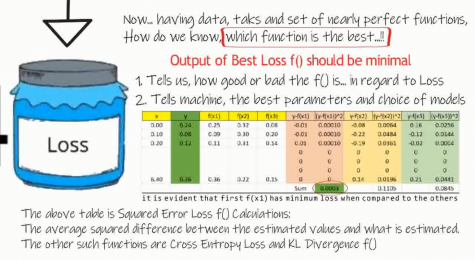
Now, we have clean data, tasks clearly identified, where we know, which set of x’s correspond to which Y’s, and also a nearly perfect function. Now the crucial question is, how effective is the function? Is this the best function? or should we have to search for more alternatives, and other such questions.
- to address this concern: we can calculate the Loss for each function.
- the more the loss, the less useful the function is. in other words,
- the effective efficiency of each function is inversely proportional to its output.
to Calculate loss, we have functions like, Squared Error Loss function, Cross Entropy function, K L Divergence function and few others.
5. LEARNING JAR
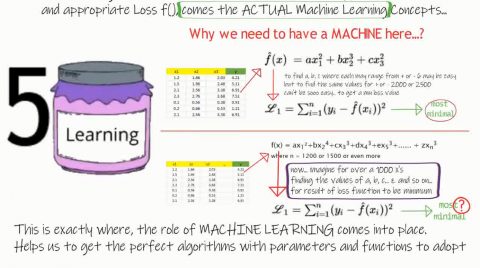
Assuming that we have successfully completed all the previous 4 steps, we come to the crucial step, where actual machine learning comes into. We may think, as to why, we need a machine here… consider the example as shown below, here we have an example with a simple equation, and the corresponding loss function.
Now we have to calculate the values for, a, b, and c, and input them into the loss function, to check if the loss is minimum, if the value range is, say for example, from -6 to +6, it looks easy, but if the results are not satisfactory, we need to try with a bigger range, say -100 to + 100.. not an easy task to work with.. isn’t it.
Let us consider another example, where we have over a thousand x’s, how the complexity grows beyond comprehension. It is highly time taking and cumbersome task to literally check for each function for all the given x’s.
This is where the point of Machine Learning comes into place. Here, we not only tell the machine to calculate the values of x’s keeping the loss to minimum, but also tell the machine to find the best algorithm to suit the requirement.
Now, the machine will come up with different suggestions for the best fit function and its respective parameters.
Thanks to the technology, and the founding fathers of this innovative idea.
Now we are ready to go ahead, with what we have accomplished till now.
6. EVALUATION JAR
The last in the final stages state six for the evaluation jar stage where all the work we have done till now was put to test. Do we really need to test? Ofcourse Yes. we have certain formula to calculate the effective efficiency of the algorithms and parameters suggested by the machine.
Here, we need to learn two terms, Precision and Recall, in generic terms, we say, true positives false positives, true negatives and false negatives. Outcomes of the machine suggestion should be measured against these four parameters.
To diffuse this confusion, let us consider two statements where an employee can say,
- either he is satisfied or
- dissatisfied, but we can come across some cases where the employee says
- “no satisfaction” which doesn’t mean “dis-satisfaction” likewise
- an employee can say "no dis-satisfaction” which doesn’t mean that he is “satisfied”.
In an ideal case scenario the prediction should be equal to the given output, else we calculate the degree of accuracy subjected to customer acceptance.
7. CLOSING JAR
Thank you for your reading time. Wish you all the best. God Bless You.